InterSystemsデータプラットフォームとパフォーマンス - パート9 InterSystems IRIS VMwareのベストプラクティスガイド
この記事ではVMware ESXi 5.5以降の環境にCaché 2015以降を導入する場合の構成、システムのサイジング、およびキャパシティ計画のガイドラインを示します。
ここでは、皆さんがVMware vSphere仮想化プラットフォームについてすでに理解していることを前提としています。 このガイドの推奨事項は特定のハードウェアやサイト固有の実装に特化したものではなく、vSphereの導入を計画して構成するための完全なガイドとして意図されたものでもありません。これは、皆さんが選択可能なベストプラクティス構成をチェックリストにしたものです。 これらの推奨事項は、皆さんの熟練したVMware実装チームが特定のサイトのために評価することを想定しています。
InterSystems データプラットフォームとパフォーマンスに関する他の連載記事のリストはこちらにあります。
注意: 本番データベースインスタンス用のVMメモリを予約し、Cachéに確実にメモリを使用させてデータベースのパフォーマンスに悪影響を与えるスワップやバルーニングの発生を防ぐ必要があることを強調するため、この記事を2017年1月3日に更新しています。 詳細については、以下のメモリセクションを参照してください。
参考情報
この記事に掲載されている情報は経験に基づいており、一般公開されているVMwareナレッジベースの記事やVMwareの各種ドキュメント(VMware vSphereのパフォーマンスのベストプラクティスなど)とCachéの導入要件への対応付けを総括しています。
InterSystemsの製品はESXiでサポートされていますか?
OSが仮想化されている場合を含め、さまざまなプロセッサのタイプとOSに対してInterSystemsの製品を検証およびリリースするのは、InterSystemsのポリシーであり、決まりでもあります。 詳細については、InterSystemsサポートポリシーおよびリリース情報を参照してください。
例えばx86ホスト上のESXiの場合、Caché 2016.1をRed Hat 7.2 OS上で実行することができます。
注意:独自のアプリケーションを作成しない場合は、アプリケーションベンダーのサポートポリシーも確認する必要があります。
サポート対象ハードウェア
VMware仮想化は、最新のサーバーとストレージコンポーネントと合わせて使用した場合に、Cachéでうまく機能します。 VMware仮想化を使用するCachéはお客様のサイトで問題なく導入されており、パフォーマンスとスケーラビリティのベンチマークで実証されています。 適切に構成されたストレージ、ネットワーク、および最新モデルのIntel Xeonプロセッサ(具体的にはIntel Xeon 5500、5600、7500、E7シリーズ、および最新のE5 v4を含むE5シリーズ)を搭載したサーバーでVMware仮想化を実施していれば、パフォーマンスに大きな影響はありません。
通常、CachéとアプリケーションはゲストOSにインストールおよび構成されますが、その方法はベアメタルインストール環境上の同じOSの場合と同じです。
使用されている具体的なサーバーとストレージについてVMwareの互換性ガイドを確認するのはお客様の責任です。
仮想化アーキテクチャ
VMwareは、次のような2つの標準的なCachéアプリケーションの構成で一般的に使用されています。
- プライマリ本番データベースのOSインスタンスが「ベアメタル」クラスターにあり、VMwareがWebサーバー、印刷、テスト、トレーニングなどの補助的な本番インスタンスや非本番インスタンスにのみ使用されている構成。
- プライマリ本番インスタンスを含むすべてのOSインスタンスが仮想化されている構成。
この記事は両方のシナリオに対応したガイドとして使用できますが、本番を含むすべてのOSインスタンスが仮想化されている2番目のシナリオに焦点を当てています。 次の図は、該当する構成用にセットアップされた典型的な物理サーバーを示しています。
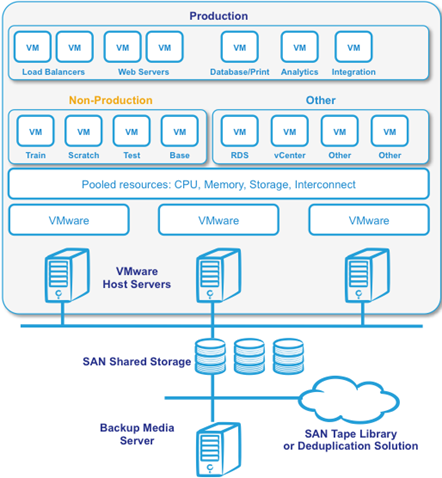
図1. 単純な仮想化されたCachéアーキテクチャ
図1は、VMware HAクラスター内のホストサーバーにN+1の容量と可用性を提供するため、少なくとも3台の物理ホストサーバーを設置している一般的な導入形態を示しています。 リソースをスケーリングするため、追加の物理サーバーをクラスターに追加できます。 バックアップ/復元用メディアの管理や災害復旧のために、追加の物理サーバーが必要になる場合もあります。
VMware vSAN、VMwareのハイパーコンバージドインフラストラクチャソリューションについては、「パート8 - ハイパーコンバージドインフラストラクチャのキャパシティとパフォーマンス計画」を参照してください。 この記事の推奨事項のほとんどはvSANに適用できます。ただし、以下の「ストレージ」セクションにある一部の明らかな違いは除きます。
VMwareのバージョン
以下の表は、Caché2015以降の主な推奨事項を示しています。

vSphereは、vCenterクライアントを介したホストと仮想マシンの集中システム管理を可能にするvCenter Serverを含む製品スイートです。
この記事では「無料」のESXiハイパーバイザーのみのバージョンではなく、vSphereが使用されることを想定しています。
VMwareにはいくつかのライセンスモデルがあります。最終的には、現在および将来のインフラストラクチャ計画に適したモデルに基づいてバージョンを選択する必要があります。
私は普段、ハードウェアをより効率的に使用するための動的リソーススケジューリング(DRS)やストレージアレイ統合(スナップショットのバックアップ)用ストレージAPIなどの追加機能が使える「Enterprise」エディションをお勧めしています。 VMwareのWebサイトには各エディションの比較情報が掲載されています。
vCenter ServerとvSphereのCPUライセンスをバンドルできるAdvanced Kitもあります。 このキットにはアップグレードに制限があるため、通常は成長が予想されない小規模なサイトにのみ推奨されます。
ESXiホストのBIOS設定
ESXiホストは物理サーバーです。 BIOSを構成する前に、次の確認を行う必要があります。
- 対象サーバーが最新のBIOSを実行していることをハードウェアベンダーに確認すること。
- VMware用のサーバー/CPUモデル固有のBIOS設定があるかどうかを確認すること。
サーバーBIOSのデフォルト設定は、VMwareには最適でない場合があります。 物理ホストサーバーを最適化して最高のパフォーマンスを得るため、以下の設定を使用することができます。 ただし、以下の表のすべての設定をあらゆるベンダーのサーバーに適用できるわけではありません。

メモリ
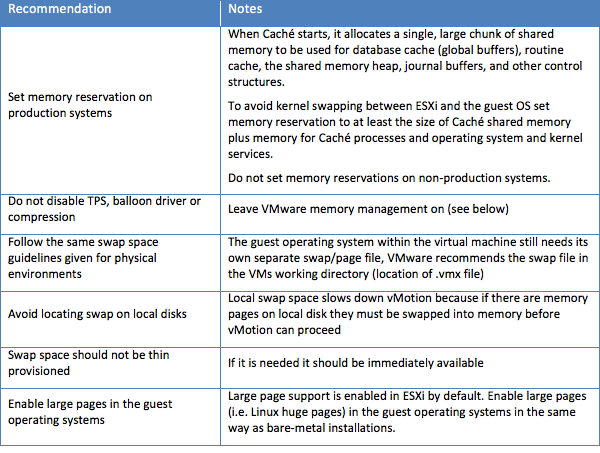
メモリの割り当てについては、以下の重要なルールを考慮する必要があります。
単一の物理ホストで複数のCachéインスタンスやその他のアプリケーションを実行する場合、VMwareには透過的なページ共有(TPS)、バルーニング、スワップ、メモリ圧縮といったメモリ管理を効率化するいくつかのテクノロジーがあります。 例えば同じホストで複数のOSインスタンスが実行されている場合、TPSはメモリ内のページの冗長なコピーを排除することにより、パフォーマンスを低下させることなくメモリのオーバーコミットを可能にします。これにより、物理マシンよりも少ないメモリで仮想マシンを実行できます。
注意: VMwareのこれらの機能やその他多くの機能を利用するには、VMware ToolsをOSにインストールする必要があります。
これらの機能はメモリのオーバーコミットを可能にするために存在しますが、常にすべてのVMのvRAMが使用可能な物理メモリ内に収まるようにサイジングすることから始めることをお勧めします。 実稼働環境ではメモリのオーバーコミットの影響を慎重に検討し、データを収集した後でのみオーバーコミットを実行し、許容できるオーバーコミットの量を判断することが特に重要です。 特定のCachéインスタンスのメモリ共有の有効性と許容可能なオーバーコミットメントの程度を判断するには、ワークロードを実行し、VMwareコマンド(resxtop または esxtopを使用して実際の節約状況を観察してください。
Cachéインスタンスのメモリ要件を計画する際には、この連載の第4回目の記事に戻って参照するのが良いでしょう。 特に、「VMware仮想化に関する考慮事項」セクションでは次の内容を指摘しています。
本番システムにVMwareの予約メモリを設定すること。
共有メモリのスワッピングは避けたい避けるべきであるため、本番データベースVMの予約メモリを、少なくともCaché共有メモリにCachéプロセス、OS、およびカーネルサービス用のメモリを加えたサイズに設定する必要があります。 不確かであれば本番データベースインスタンス用のVMメモリを予約し(100%予約)、Cachéに確実にメモリを使用させてデータベースのパフォーマンスに悪影響を与えるスワップやバルーニングの発生を防いでください。
注意: 大容量のメモリを予約するとvMotionの操作に影響があるため、vMotion/管理ネットワークを設計する際にはこの事を考慮することが重要です。 仮想マシンはターゲットホストに予約したサイズ以上の空き物理メモリがある場合にのみ、ライブマイグレーションまたはVMware HAの機能を備えた別のホストで起動することができます。 これは本番のCaché VMでは特に重要です。 例えば、HAアドミッションコントロールポリシーに特に注意してください。
キャパシティプランニングにより、HAフェイルオーバーが発生した場合にVMを配布できるようにしてください。
非本番環境(テスト、トレーニングなど)ではより積極的にメモリをオーバーコミットできますが、Cachéの共有メモリはオーバーコミットしないでください。代わりに、グローバルバッファを減らすことでCachéインスタンスの共有メモリを制限してください。
現行のIntelプロセッサアーキテクチャには、NUMAトポロジがあります。 各プロセッサには独自のローカルメモリがあり、同じホスト内の他のプロセッサのメモリにアクセスできます。 当然のことながら、ローカルメモリにアクセスした場合はリモートメモリにアクセスする場合よりもレイテンシが低くなります。 CPUの説明については、コメントセクションでNUMAに関する議論が行われている、この連載の3番目の記事をご覧ください。
上記のBIOSセクションで述べたように、最適なパフォーマンスを実現するにはVMのサイズを単一プロセッサのコアとメモリの最大数までに制限するのが得策です。 例えば、キャパシティプランニングにより本番環境で最大のCachéデータベースVMが14個のvCPUと112 GBのメモリを使用することになることが判明した場合、2x E5-2680 v4(14コアプロセッサ)と256 GBのメモリを搭載したサーバーのクラスターが適しているかどうかを検討してください。
理想的には、メモリをNUMAノードに対してローカルに維持できるようにVMのサイズを決定してください。 しかし、これにこだわりすぎる必要はありません。
NUMAノードより大きな「モンスターVM」が必要な場合は、それでもかまいません。VMwareがNUMAを管理して最適なパフォーマンスを実現します。 また、VMを適正化して、必要以上のリソースを割り当てないようにすることも重要です(以下を参照してください)。
CPU
仮想CPUの割り当てについては、次の重要なルールを考慮する必要があります。

本番Cachéシステムのサイジングは、実際の顧客サイトのベンチマークと測定に基づいて行われるべきです。 本番システムには、ベアメタルのCPUコアと同じようにシステムのサイズを最初に決定し、ベストプラクティスに従って仮想CPU(vCPU)を削減できるかどうかを監視する戦略を使用してください。
ハイパースレッディングとキャパシティプランニング
物理サーバーに関するルールに基づいて本番データベースVMのサイジングに着手するには、まず、ハイパースレッディングが有効化された状態でターゲットプロセッサに対する物理サーバーのCPU要件を計算し、それを次のように単純に変換してください。
1つの物理CPU(ハイパースレッディングを含む)= 1つのvCPU(ハイパースレッディングを含む)
ハイパースレッディングによってvCPUキャパシティが2倍になるという誤解が一般的にありますが、 これは、物理サーバーまたは論理vCPUには当てはまりません。 ベアメタルサーバーでハイパースレッディングを使用すると、ハイパースレッディングを使用しない同じサーバーよりもパフォーマンスが30%向上する可能性がありますが、この数値もアプリケーションによって異なる可能性があります。
初期サイジングでは、vCPUが完全な専用のコアを持つことを想定しています。 例えば32コア(2✕16コア)E5-2683 V4サーバーを使用している場合は、利用できるヘッドルームがあることを確認して、最大32vCPUキャパシティの合計になるようにサイジングします。 この構成では、ホストレベルでハイパースレッディングが有効化されていることが前提です。 VMwareは、ホスト上のすべてのアプリケーションとVM間のスケジューリングを管理します。 ピーク処理期間のアプリケーション、OS、およびVMwareのパフォーマンスをしばらく監視したら、より高い整理統合が可能であるかどうかを判断することができます。
ライセンス
vSphereでは、特定の数のソケットまたはコアを持つVMを構成できます。 たとえば、デュアルプロセッサVM(2 vCPU)を使用している場合、2つのCPUソケット、または2つのCPUコアを持つ単一のソケットとして構成することができます。 VMが1つの物理ソケットで実行するのか2つの物理ソケットで実行するのかは、最終的にハイパーバイザーが決定するため、実行の観点からは、大きな違いはありません。 しかし、デュアルCPU VMに実際には2つのソケットではなく2つのコアがあると指定すると、ソフトウェアライセンスに違いが生じる可能性があります。 注意: Cachéライセンスではコア数(スレッド数ではない)が考慮されます。
ストレージ
このセクションの内容は、共有ストレージアレイを使用する従来のストレージモデルに適用されます。 vSANの推奨事項については、「パート8 - ハイパーコンバージドインフラストラクチャのキャパシティとパフォーマンス計画」も参照してください。
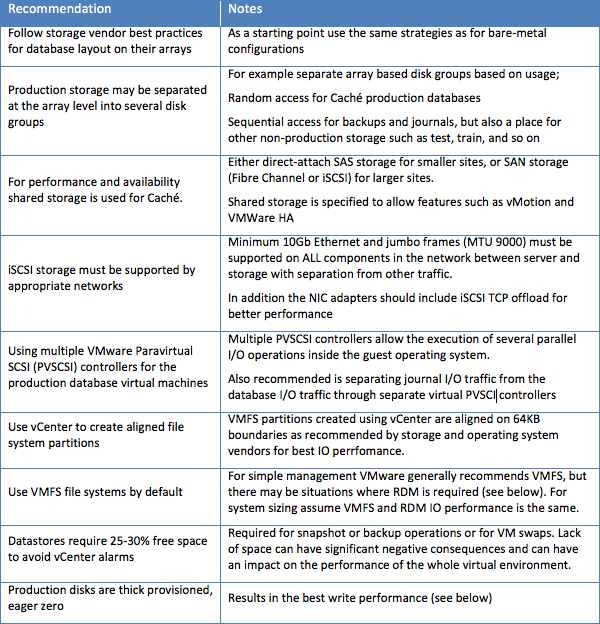
ストレージについては、以下の重要なルールを考慮する必要があります。
パフォーマンスを向上させるストレージのサイジング
ストレージのボトルネックは、Cachéシステムのパフォーマンスに影響を与える最も一般的な問題の1つです。これはVMware vSphereの構成についても当てはまります。 最も一般的な問題は、予想される1秒あたりのIOPSをサポートするのに十分な数の物理ディスクを割り当てるのではなく、単にGB容量に合わせてストレージのサイズを決定することです。 VMwareでは同じ物理接続を介してより多くのホストが同じストレージにアクセスできるため、ストレージの問題がさらに深刻になる場合があります。
VMwareストレージの概要
VMwareのストレージ仮想化は、例えば次の3つの層に分類できます。
- ストレージアレイは最下層であり、上位層に論理ディスク(ストレージアレイボリュームまたはLUN)として提示される物理ディスクで構成されています。
- 次の層はvSphereが占有する仮想環境です。 ストレージアレイのLUNはデータストアとしてESXiホストに提示され、VMFSボリュームとしてフォーマットされます。
- 仮想マシンはデータストア内のファイルで構成され、仮想ディスクはパーティションを切ってファイルシステムで使用できるディスクとしてゲストOSに提供されます。
VMwareは仮想マシンのディスクアクセスを管理するため、VMware仮想マシンファイルシステム(VMFS)とRawデバイスマッピング(RDM)の2つの選択肢を提供していますが、どちらのパフォーマンスもほぼ同じです。 管理を単純化するため、VMwareは一般的にVMFSを推奨していますが、RDMが必要な状況もあるかもしれません。 一般的にはRDMを使用する特別な理由がない限り、VMFSを選択することが推奨されています。VMwareによる新しい開発は、RDMではなくVMFSを対象としています。
仮想マシンファイルシステム(VMFS)
VMFSはVMwareによって開発されたファイルシステムであり、クラスター化された仮想環境(複数のホストから読み取り/書き込みアクセス可能)および大容量ファイルのストレージ専用に最適化されています。 VMFSの構造ではVMファイルを単一のフォルダーに格納できるため、VMの管理が単純化されます。 VMFSは、vMotion、DRS、VMware HAなどのVMwareインフラストラクチャサービスも使用可能にします。
OS、アプリケーション、およびデータは、仮想ディスクファイル(.vmdkファイル)に格納されます。 vmdkファイルはデータストアに格納されます。 単一のVMを複数のデータストアに分散された複数のvmdkファイルで構成することができます。 以下の図の本番VMが示すように、VMには複数のデータストアにまたがるストレージを含めることができます。 本番システムでは、LUNごとに1つのvmdkファイルで最高のパフォーマンスが得られます。非本番システム(テスト、トレーニングなど)では、複数のVMのvmdkファイルがデータストアとLUNを共有できます。
vSphere 5.5の最大VMFSボリュームサイズは64 TB、最大VMDKサイズは62 TBですが、Cachéを導入する場合は別々のディスクグループのLUNにマップされた複数のVMFSボリュームを使用し、IOパターンを分離してパフォーマンスを向上させるのが一般的です。 例えばランダムIOとシーケンシャルIOのディスクグループを分離したり、本番環境のIOと他の環境のIOを分離したりします。
以下の図は、Cachéで使用されるVMware VMFSストレージの例の概要を示しています。
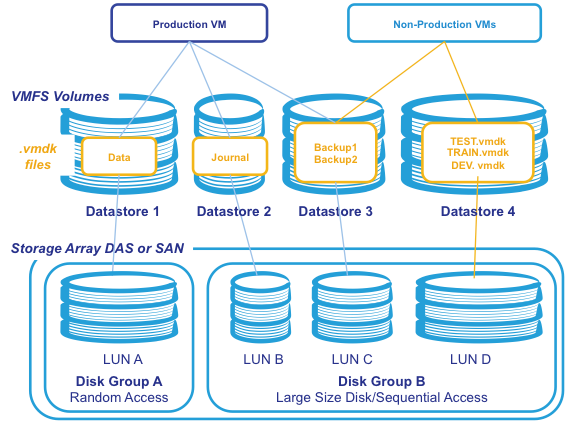
図2. VMFS上のCachéストレージの例
RDM
RDMを使用すると、物理的なSCSIディスクまたはLUNをVMFSファイルとして管理およびアクセスできます。 RDMは物理デバイスのプロキシの代わりに機能するVMFSボリューム上の特別なファイルです。 ほとんどの仮想ディスクストレージにはVMFSが推奨されますが、場合によっては物理ディスクが望ましい場合があります。 RDMはファイバチャネルストレージまたはiSCSIストレージでのみ使用できます。
VMware vStorage APIs for Array Integration(VAAI)
最高のストレージパフォーマンスを得るには、VAAI対応のストレージハードウェアの使用を検討する必要があります。 VAAIは、仮想マシンのプロビジョニングやシンプロビジョニングされた仮想ディスクなど、いくつかの領域でパフォーマンスを向上させることができます。 VAAIは、古いアレイのアレイベンダーからファームウェアアップデートとして入手できる場合があります。
仮想ディスクタイプ
ESXiは複数の仮想ディスクタイプをサポートしています。
シックプロビジョニングでは作成時に容量が割り当てられます。 さらに次のタイプに分かれています。
- Eager Zeroed – ドライブ全体に0を書き込みます。 このため、ディスク作成にかかる時間は増えますが、各ブロックへ初めて書き込む場合でも最高のパフォーマンスが得られます。
- Lazy Zeroed – 各ブロックへ初めて書き込むときに0を書き込みます。 Lazy Zeroedの場合は作成時間が短くなりますが、ブロックが初めて書き込まれるときのパフォーマンスは低下します。 ただし、それ以降の書き込みはEager-Zeroedシックディスクの場合と同じパフォーマンスになります。
シンプロビジョニングでは書き込み時に容量が割り当てられ、ゼロアウトされます。 書き込みが行われていないファイルブロックへ最初に書き込むときにはI/Oコストが高くなります(Lazy Zeroedのシックディスクの場合と同様)が、それ以降の書き込みでは、シンプロビジョニングされたディスクのパフォーマンスはEager Zeroedのシックディスクと同じです。
どのディスクタイプでも、VAAIはストレージアレイに処理をオフロードすることでパフォーマンスを向上させることができます。一部のアレイはアレイレベルでのシンプロビジョニングもサポートしていますが、シンプロビジョニングされたアレイストレージでESXiのディスクをシンプロビジョニングしないでください。プロビジョニングと管理で競合が発生する可能性があるためです。
その他の注意事項
上記のベストプラクティスのとおり、ベアメタル構成と同じ戦略を使用してください。本番ストレージは、次のようにアレイレベルでいくつかのディスクグループに分割できます。
- Caché本番データベースへのランダムアクセス用
- バックアップとジャーナルへのシーケンシャルアクセス、およびテスト、トレーニングなどの他の非本番ストレージ用
データストアはストレージ階層を抽象化したものであり、ストレージの物理的な表現ではなく論理的な表現であることを覚えておいてください。 物理ストレージレイヤーを分離せずに特定のI/Oワークロード(ジャーナルファイルかデータベースファイルかを問わず)を分離するために専用のデータストアを作成した場合も、パフォーマンスに望ましい影響はありません。
パフォーマンスは重要ですが、どのような共有ストレージを選択すべきかは、VMwareの影響よりも拠点内の既存インフラストラクチャや予定されているインフラストラクチャによって決まります。 ベアメタル実装と同様、ファイバチャネルSANが最もパフォーマンスが高く、推奨されます。 ファイバチャネルの場合、8Gbpsアダプタが推奨最小値です。 iSCSIストレージは、適切なネットワークインフラストラクチャが導入されている場合にのみサポートされます。例えば、他のトラフィックから分離されたサーバーとストレージ間のネットワーク内のすべてのコンポーネントが10Gb以上のイーサネットとジャンボフレーム(MTU 9000)をサポートしていなければなりません。
データベース用の仮想マシンやI/O負荷の高い仮想マシンには、複数のVMware準仮想化SCSI(PVSCSI)コントローラーを使用してください。 PVSCSIはCPU使用率を削減しながら全体的なストレージスループットを向上させるため、かなりのメリットをもたらします。 複数のPVSCSIコントローラーを使用すると、ゲストOS内で複数の並列I/O操作を実行できるようになります。 また、独立した仮想化SCSIコントローラーを使用し、データベースI/OトラフィックからジャーナルI/Oトラフィックを切り離すことをお勧めします。 ベストプラクティスとしては、1つのコントローラーをOSとスワップに使用し、別のコントローラーをジャーナルに使用し、(データベースのデータファイルの数とサイズに応じて)1つ以上の追加コントローラーをデータベースデータファイルに使用できます。
データベースのワークロードに対応するためのベストプラクティスとしては、ファイルシステムのパーティションを調整することがよく知られています。 物理マシンとVMware VMFSパーティションの両方でパーティションを調整することで、I/Oがトラック境界を越えることでI/Oパフォーマンスが低下するのを防ぎます。 VMwareをテストした結果、VMFSパーティションを64KBのトラック境界に合わせると遅延が減少し、スループットが向上することが分かっています。 vCenterを使用して作成されたVMFSパーティションは、ストレージおよびOSのベンダーが推奨する64KB境界に合わせられます。
ネットワークの構築
ネットワークの構築については、以下の重要なルールを考慮する必要があります。
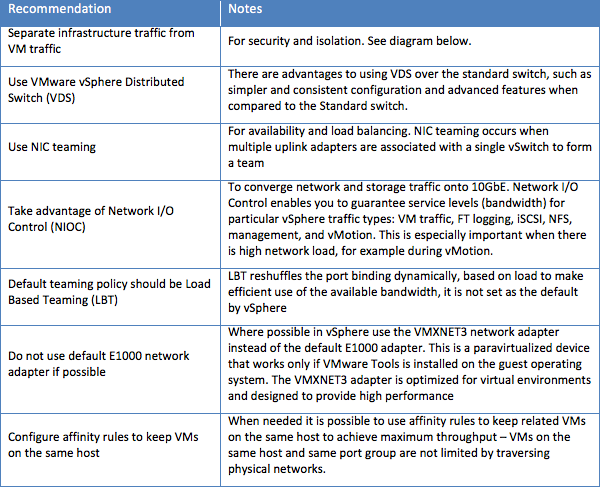
上記のように、VMXNETアダプタはデフォルトのE1000アダプタよりも優れた機能を備えています。 E1000は1Gbにしか対応していませんが、VMXNET3は10Gbに対応しており、CPU使用率も低くなります。 ホスト間に1ギガビットのネットワーク接続しかなければ、クライアントとVMの通信に大きな違いはありません。 ただし、VMXNET3を使用すると同一ホスト上のVMが10Gbで通信できます。そのため、特に多層デプロイやインスタンス間に高いネットワークIO要件がある場合には違いが生じます。 この機能は、VMを同一の仮想スイッチまたは別々の仮想スイッチ上に維持するためにアフィニティおよび非アフィニティDRSルールを計画するときにも考慮する必要があります。
E1000はWindowsまたはLinuxで使用できる汎用ドライバーを使用します。 ゲストOSにVMware Toolsをインストールしたら、VMXNET仮想アダプタをインストールできます。
次の図は、4つの物理NICポートを備えた典型的な小規模サーバー構成を示しており、インフラストラクチャトラフィック用に2つのポート(管理およびvMotion用のdvSwitch0と、VMがアプリケーションに使用する2つのポート)がVMware内に構成されています。 最高のスループットと高可用性を実現するため、NICチーミングとロードバランシングが使用されています。

図3. 4つの物理NICポートを備えた典型的な小規模サーバー構成。
ゲストOS
以下が推奨されます。

VMwareツールをすべてのVM OSにロードし、ツールを最新の状態に保つことが非常に重要です。
VMware Toolsは仮想マシンのゲストOSのパフォーマンスを向上し、仮想マシンの管理機能を強化するユーティリティスイートです。 ゲストOSにVMware Toolsがインストールされていない場合、ゲストにはパフォーマンスと重要な機能が不足することになります。
すべてのESXiホストで必ず時刻を正しく設定してください。最終的にはゲストVMに影響します。 VMのデフォルト設定ではゲストとホストの時刻は同期していません。ただし、それでも特定のタイミングでゲストはホストと時刻を同期し、その際に時刻が合わないと大きな問題が発生することが分かっています。 VMwareは、VMware Toolsによる定期的な時刻同期ではなく、NTPを使用することを推奨しています。 NTPは業界標準であり、ゲストが確実に正確な時刻を維持できるようにします。 NTPトラフィックを許可するには、ファイアウォールで必要なポート(UDP 123)を開く必要があるかもしれません。
DNS設定
仮想化インフラストラクチャでホストされているDNSサーバーが使用できなくなった場合、vCenterはホスト名を解決できなくなり、仮想環境を管理できなくなります。ただし、仮想マシン自体は問題なく動作し続けます。

高可用性
高可用性は、VMware vMotion、VMware Distributed Resource Scheduler(DRS)、VMware High Availability(HA)などの機能によって提供されます。 Cachéデータベースのミラーリングを使用して稼働時間を増やすこともできます。
重要なのは、Cachéの本番システムをn+1の物理ホストで設計することです。 単一のホストに障害が発生した場合に残りのホストですべてのVMを実行するには、十分なリソース(CPUやメモリなど)が必要です。 サーバーに障害が発生した場合にVMwareが残りのサーバーに十分なCPUリソースとメモリリソースを割り当てることができないと、VMware HAは残りのサーバーのVMを再起動できません。
vMotion
vMotionはCachéと併用できます。 vMotionを使用すると、稼働中のVMをあるESXiホストサーバーから別のESXiホストサーバーに完全に透過的に移行できます。 OSやVMで実行中のCachéなどのアプリケーションがサービスを中断することはありません。
vMotionを使用して移行する場合、VMの状態とメモリ(およびその構成)のみが移動します。 仮想ディスクを移動する必要はありません。仮想ディスクは同じ共有ストレージの場所に残ります。 移行後のVMは新しい物理ホストで稼働します。
vMotionは共有ストレージアーキテクチャ(共有SASアレイ、ファイバチャネルSAN、iSCSIなど)でのみ機能します。 Cachéは一般的に大量の共有メモリを使用するように構成されているため、vMotionで十分なネットワーク容量を使用できるようにしなければなりません。1Gbのネットワークで十分な場合もありますが、より高い帯域幅が必要な場合もあります。または、マルチNIC vMotionを構成することもできます。
DRS
Distributed Resource Scheduler(DRS)はクラスター内の異なるホストサーバー間でワークロードを共有することにより、本番環境で自動的にvMotionを使用します。
DRSはVMインスタンスにQoSを実装し、リソースを過剰に使用している非本番VMを停止して本番VMのリソースを保護する機能も提供します。 DRSはクラスター内の各ホストサーバーの使用状況に関する情報を収集し、クラスター内の各サーバー間でVMのワークロードを分散してリソースを最適化します。 この移行は、自動または手動で実行できます。
Cachéデータベースミラー
最高の可用性を必要とするミッションクリティカルな最上位のCachéデータベースアプリケーションインスタンスの場合、InterSystemsの同期データベースミラーリングを使用することも検討してください。ミラーリングを使用すると次のようなメリットもあります。
- 最新データの独立したコピーが存在します。
- 秒単位でフェイルオーバーできます(VMを再起動してからオペレーティングシステムを起動し、Cachéをリカバリするよりも高速です)。
- アプリケーション/Cachéに障害が発生した場合(VMwareでは検出されません)にフェイルオーバーできます。
vCenter アプライアンス
vCenter Server Applianceは事前構成されたLinuxベースの仮想マシンであり、vCenter Serverおよび関連サービスを実行するために最適化されています。 私は小規模なクラスターのある拠点にはWindows VMにvCenter Serverをインストールする代わりに、VMware vCenter Server Applianceを使用することを推奨しています。 vSphere 6.5では、あらゆる導入でアプライアンスを使用することが推奨されています。
要約
この記事は、CachéをVMwareに導入する際に検討する必要がある主なベストプラクティスをまとめたものです。 これらのベストプラクティスのほとんどはCachéに固有のものではありませんが、他の最上位のビジネスクリティカルアプリケーションをVMwareに導入する場合に適用できます。
ご質問がある場合は、以下のコメント欄でお知らせください。